

自上次国际象棋被“深蓝”单挑了之后,棋类似乎只剩下围棋人类能够一战。之前一致认为围棋的可能性太多,基本上有10的170次方的走法,从之前编程的角度来说似乎机器是不可能赢的。但是神经网络的出现和机器学习的发展,让计算机能够模拟人类的思考方式进行分析,从而在围棋以及其他高难度方面能够交给计算机处理。
下面的图是AlphaGO第三天赢李世石的最终棋谱:

AlphaGO VS LEE
虽然对围棋不是很了解,但是在解说的帮助下似乎还是可以看出AlphaGO对于局势的判断和走棋的方式,已经形成自己的风格,并且走棋稳定。这其实已经说明AlphaGO对于信息处理和价值判断不存在什么大问题了。
关于AlphaGO是如何做到的,下面摘自新闻上的一段话可以描述一下:
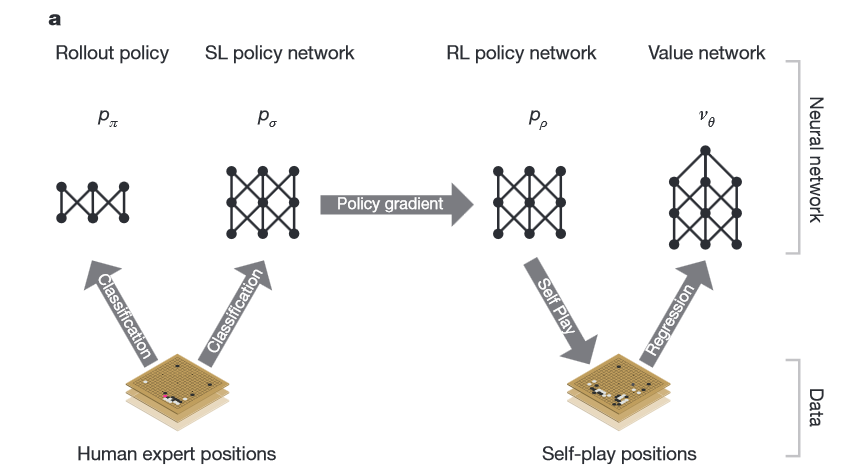
Neural network training pipeline and architecture
谷歌公司称,传统的人工智能方法是将所有可能的走法构建成一棵搜索树 ,但这种方法对围棋并不适用。所以在征服围棋的过程中,谷歌决定另辟蹊径,构建了AlphaGo的系统,将高级搜索树与深度神经网络结合在一起。
这些神经网络通过12个处理层传递对棋盘的描述,这些处理层包含数百万个类似于神经的连接点。其中一个神经网络“策略网络”(policy NETwork)选择下一步走法,另一个神经网络“价值网络”(value network)预测比赛胜利者。
谷歌用人类围棋高手的三千万步围棋走法训练神经网络,直至神经网络预测人类走法的准确率达到57%。为了打败樊麾,AlphaGo学习自行研究新战略,在它的神经网络之间运行了数千局围棋,利用反复试验调整连接点,这个流程也称为巩固学习。 完成训练后,谷歌再对AlphaGo进行测试。首先,谷歌在AlphaGo和其他顶级计算机围棋程序之间举行了比赛,结果AlphaGo在全部500场比赛中只输了一场。下一步就是邀请欧洲围棋三料冠军樊麾来到谷歌的伦敦办公室参加挑战赛,结果大家已经知道了。
最后附上AlphaGO团队在Nature上发表的论文:
Mastering the game of Go with deep neural networks and tree search
